在 Coiled 中使用 uv
Coiled 是一个无服务器、以用户体验为中心的云计算平台,让你可以轻松地在云硬件(AWS、GCP 和 Azure)上运行代码。
本指南将展示如何使用 uv 进行依赖管理、使用 Coiled 进行云部署,从而在云端运行 Python 脚本。
使用 uv 管理脚本依赖
Note
我们将在本指南中全程使用这个具体示例,但任何 Python 脚本都可以与 uv 和 Coiled 配合使用。
我们以以下脚本为例:
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "pandas",
# "pyarrow",
# "s3fs",
# ]
# ///
import pandas as pd
df = pd.read_parquet(
"s3://coiled-data/uber/part.0.parquet",
storage_options={"anon": True},
)
print(df.head())
该脚本使用 pandas 加载托管在 S3 公有存储桶中的 Parquet 文件,然后打印前几行数据。它使用内联脚本元数据来枚举其依赖项。
在本地运行此脚本时,例如使用:
uv 将自动创建虚拟环境并安装其依赖项。
要了解更多关于在 uv 中使用内联脚本元数据的信息,请参阅脚本指南。
使用 Coiled 在云端运行脚本
使用内联脚本元数据使脚本完全自包含:它包含了运行所需的信息。这使得它更容易在其他机器上运行,比如云端机器。
在许多使用场景中,需要超出本地工作站所能提供的资源,例如:
- 处理大量托管在云端的数据
- 需要加速硬件,如 GPU 或具有更多内存的大型机器
- 使用数百或数千个不同的输入并行运行同一个脚本
Coiled 让在云硬件上运行代码变得简单。
首先,使用 coiled login 进行 Coiled 身份认证:
如果你还没有 Coiled 账户,系统会提示你创建一个——开始使用 Coiled 是免费的。
要指示 Coiled 在 AWS 的虚拟机上运行该脚本,请在文件顶部添加两行注释:
# COILED container ghcr.io/astral-sh/uv:debian-slim
# COILED region us-east-2
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "pandas",
# "pyarrow",
# "s3fs",
# ]
# ///
import pandas as pd
df = pd.read_parquet(
"s3://coiled-data/uber/part.0.parquet",
storage_options={"anon": True},
)
print(df.head())
Tip
虽然 Coiled 支持 AWS、GCP 和 Azure,但本示例假设使用 AWS(参见上方的 region 选项)。如果你是 Coiled 新用户,你将自动获得一个在 AWS 上运行的免费账户。如果你不在 AWS 上运行,可以使用适合你云服务提供商的有效 region 值,或者删除上面的 region 行。
这些注释告诉 Coiled 在运行脚本时使用官方的 uv Docker 镜像(确保 uv 可用),并在 AWS 的 us-east-2 区域运行(该示例数据文件恰好位于此处),以避免任何数据出站费用。
要提交批处理作业供 Coiled 运行,请使用 coiled batch run 在云端执行 uv run 命令:
之前在本机运行的相同进程现在正在 AWS 上的远程云虚拟机中运行。
你可以在 cloud.coiled.io 的 UI 中监控批处理作业的进度,也可以在终端中使用 coiled batch status、coiled batch wait 和 coiled batch logs 命令来监控。
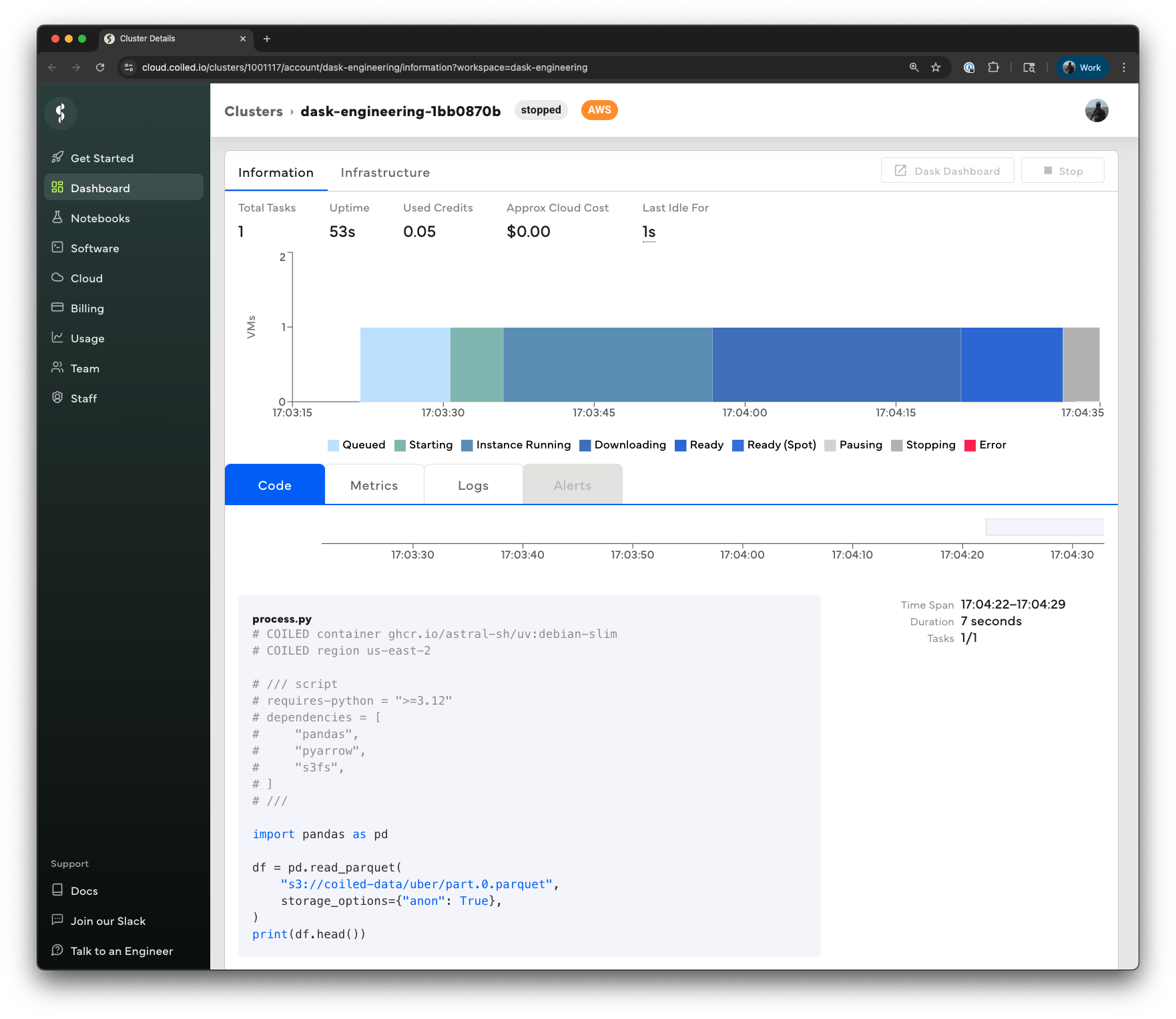
请注意,我们还可以指定其他配置,例如实例类型(默认为 4 核虚拟机,配备 16 GiB 内存)、磁盘大小、是否使用竞价实例等。更多详情请参阅 Coiled 批处理文档。
有关 Coiled 的更多详细信息,以及它如何帮助解决其他使用场景,请参阅 Coiled 文档。